VLM-Based Robotic Manipulation
Building a Natural Language to Robot Actions Pipeline
What I Built
A complete pipeline that lets you tell a robot "put the red block on the green one" and it just works - handling perception, planning, execution, and even checking its own work. The system combines computer vision (SAM2), large language models (Google Gemini), and inverse kinematics control to autonomously execute block stacking tasks in simulation.

Tech Stack: NVIDIA Isaac Sim, SAM2, Google Gemini API, Python, OpenCV, IK Control
Bottom Line: 100% success on trained tasks, 60% generalization to novel instructions, 94% perception accuracy after optimization
🎥 System Demo
Watch the full pipeline in action - from natural language input to successful execution, including a failure recovery example where self-checking saves the day.
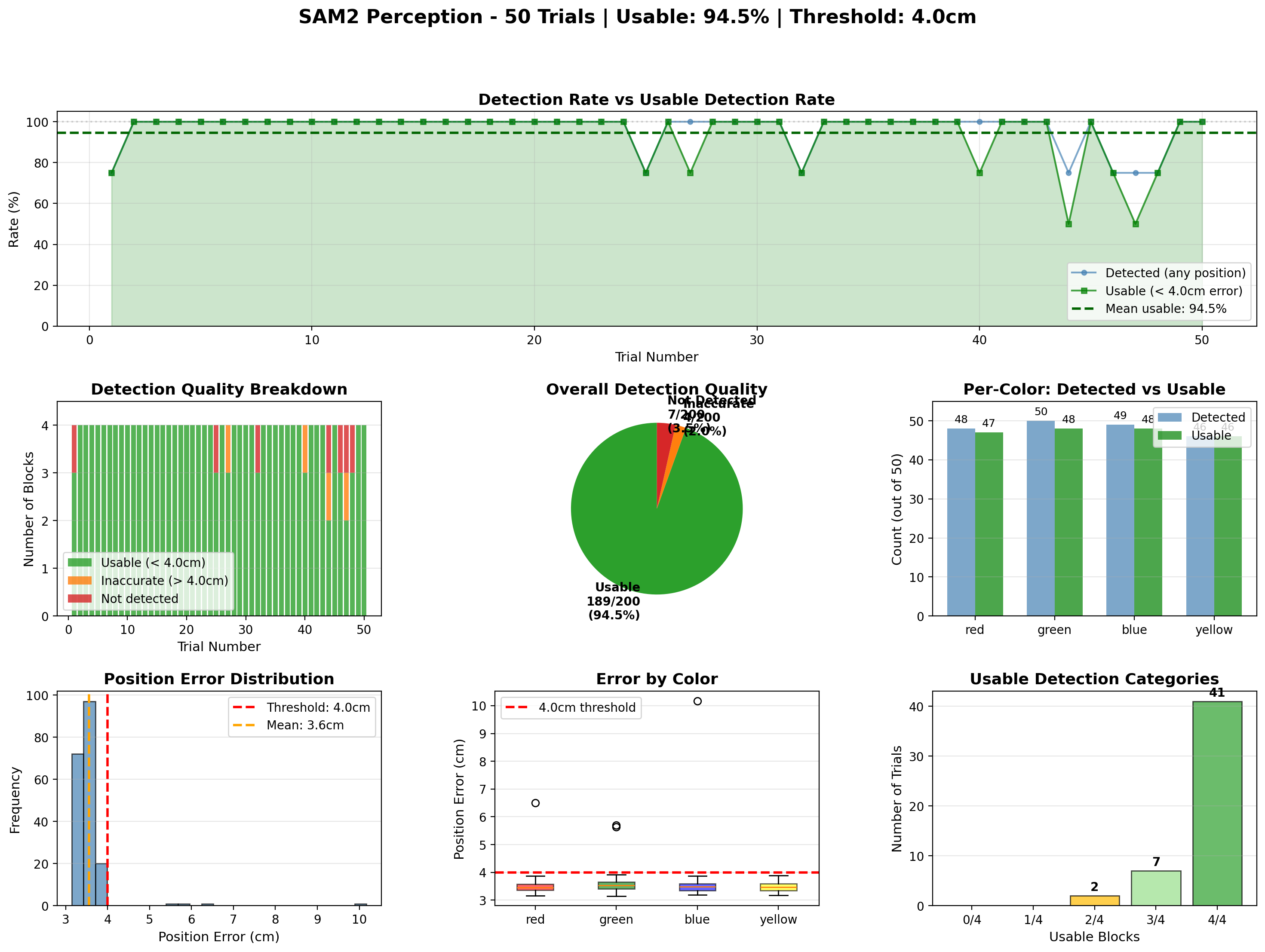
The Perception Challenge: From 30% to 94% Accuracy
Getting a robot to reliably see colored blocks sounds simple until you actually try it. I evaluated three different approaches and learned a lot about the trade-offs between accuracy, speed, and reliability.


How I Optimized SAM2
SAM2's automatic mask generation was struggling, especially with the blue block. The breakthrough came from preprocessing - instead of letting SAM2 find everything, I used color-based centroid detection to give it targeted prompts. Combined with area filtering to reject noise and distractors, this brought detection rates from 30% to 94.5% while cutting inference time by 3x.
Key techniques: HSV color thresholding → connected components → centroid extraction → SAM2 point prompts → area-based filtering
VLM Planning & Self-Checking
I tested three Gemini models to see how well they could generate structured action plans from free-form language. The interesting part wasn't just getting them to plan, but figuring out when and how to use self-checking without causing more problems than it solved.
Task Examples
In-Distribution (8 tasks): Direct commands like "Put the red block on green block" or "Stack yellow on blue"
Out-of-Distribution (4 tasks): Novel phrasings like "Make a tower on the blue block with red block" or complex multi-step "Make a 3 block stack with red, yellow and blue from bottom to top"
Example Plan: "Make a tower on the blue block with red block"
{
"plan": [
{"skill": "pick", "obj": "red"},
{"skill": "place_on", "obj": "red", "ref": "blue"}
]
}✓ Correct - the VLM correctly interpreted "tower" and "on the blue block"
Where they all failed: "Put red on yellow, then unstack yellow onto green"
❌ All three models generated invalid plans - they didn't understand that you can't move yellow while red is sitting on top of it. This revealed a fundamental limitation in spatial reasoning.
The Self-Check Dilemma
I implemented self-checking where the VLM looks at the scene after each skill and verifies success. Sounds great in theory, but it caused unexpected issues - the VLM would sometimes say "no" when blocks were partially occluded, triggering unnecessary replanning. I tested three strategies:
- Per-skill checking: High false negative rate, constant replanning
- Final-only checking: Most robust, only verifies at the end
- No checking: Better for simple tasks, fails on execution errors
The winner? Final-only checking - it caught real failures without being too sensitive to minor occlusions.
Results: Comparing Three Gemini Models
I ran 45 total episodes across three conditions (in-distribution without distractor, in-distribution with distractor, out-of-distribution with distractor) to see how each model performed.
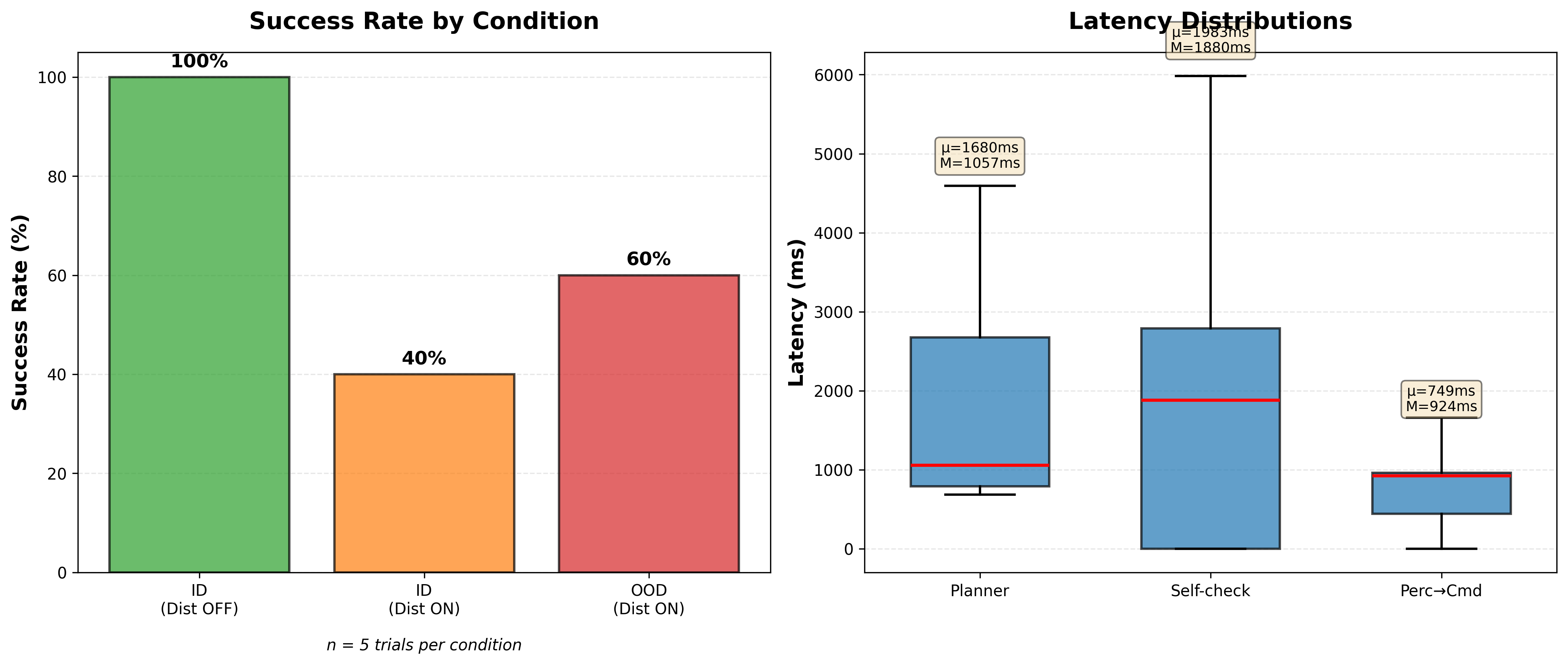
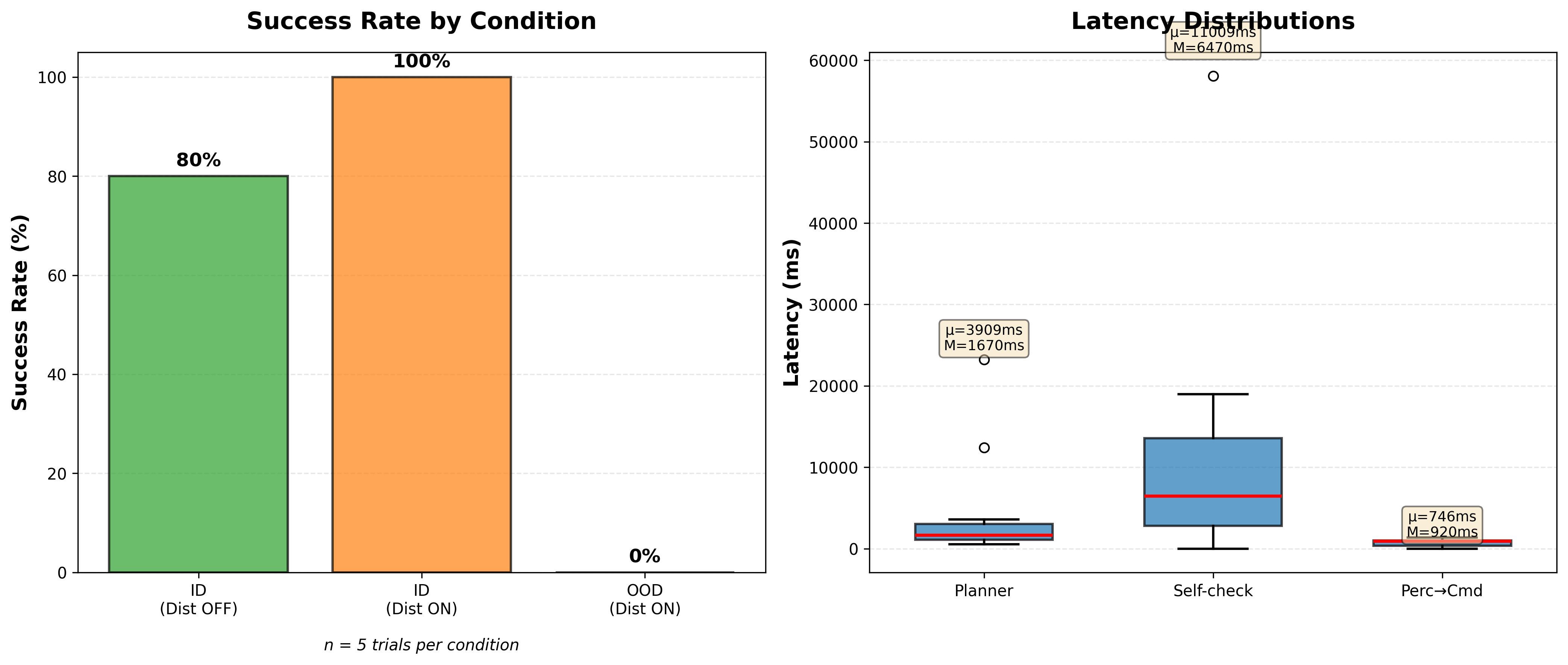
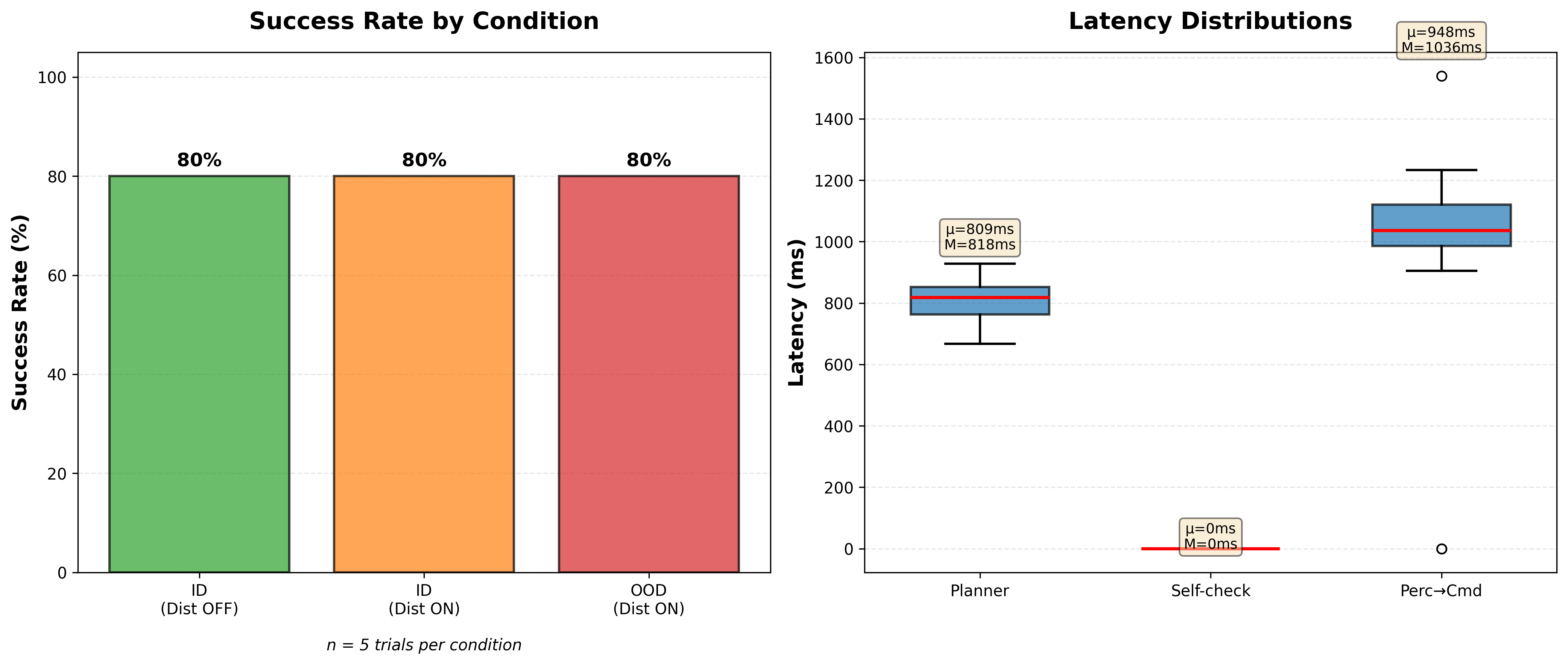
Key Findings
- Perception is the bottleneck: Even with dual-layer SAM2 + Gemini verification, occlusion from the distractor caused most failures
- Self-checking helps but has trade-offs: Improved recovery from real failures, but added 5-6s latency and occasional false negatives
- Model selection matters: Premium models aren't always better - depends on your specific use case and cost constraints
- Latency breakdown: Perception (~880ms), Planning (750-2500ms), Self-check (5-6s when used)
Real Recovery Example
In one trial, a block fell during manipulation. The self-check caught it, regenerated the plan, and successfully completed the task after 2 replanning attempts. Total time: 87.9s with 3 self-check calls. This is exactly the kind of robustness you need for real-world deployment.
What I Learned
Technical Insights
- Robust perception beats sophisticated planning every time
- Preprocessing can be more valuable than model upgrades
- Self-verification is powerful but needs careful tuning
- VLMs excel at high-level reasoning but struggle with complex spatial logic
- Systematic evaluation reveals non-obvious trade-offs
Engineering Process
- Start with metrics - track everything from day one
- Compare multiple approaches quantitatively
- Optimize the biggest bottleneck first
- Test edge cases and failure modes deliberately
- Document trade-offs for future decision-making
Future Work
The next steps would focus on moving toward real-world deployment:
- Knowledge distillation: Compress larger models for edge deployment with lower latency
- Multi-view perception: Add additional cameras to handle occlusions more robustly
- Sim-to-real transfer: Validate on physical hardware with domain randomization techniques
- Hybrid planning: Combine VLM high-level reasoning with classical motion planning for collision avoidance
- Failure case learning: Build a dataset of failures to improve few-shot prompting