Adaptive Reinforcement Learning for Robust Navigation
A Comparative Study of PPO and SAC for Autonomous Navigation in Uncertain Environments
Introduction & Motivation
Autonomous navigation in complex and unpredictable environments is a significant challenge in robotics. While traditional path planning excels in static, known settings, it often falters when faced with dynamic obstacles, sensor noise, or unexpected environmental changes. This project, inspired by the work of Cimurs et al. (2022) on goal-driven autonomous exploration, delves into developing adaptive navigation policies using advanced reinforcement learning (RL) techniques. The primary aim was to compare the effectiveness of leading on-policy (PPO) and off-policy (SAC) RL algorithms for robust navigation under uncertainty.
The Challenge: Navigation Under Uncertainty
The core technical problem was to develop an RL policy for a differential-drive robot to navigate from a start to a goal position in a 2D environment populated with static obstacles of unknown shapes and placements. The policy needed to achieve this while avoiding collisions, minimizing path length and time, adapting to different obstacle configurations, and generalizing to unseen scenarios.
The task was formalized as a Markov Decision Process (MDP) with a state space including robot pose and sensor readings (Lidar, relative goal position), and a continuous action space for angular velocity. A shaped reward function was designed to encourage goal achievement, collision avoidance, efficiency, and progress towards the goal.
Simulation Environments & Approach
To facilitate efficient training and robust validation, a two-pronged simulation strategy was adopted. Initially, performance challenges with NVIDIA's Isaac Sim in terms of training speed and vectorization led to the development of a custom, lightweight Gymnasium-based environment.
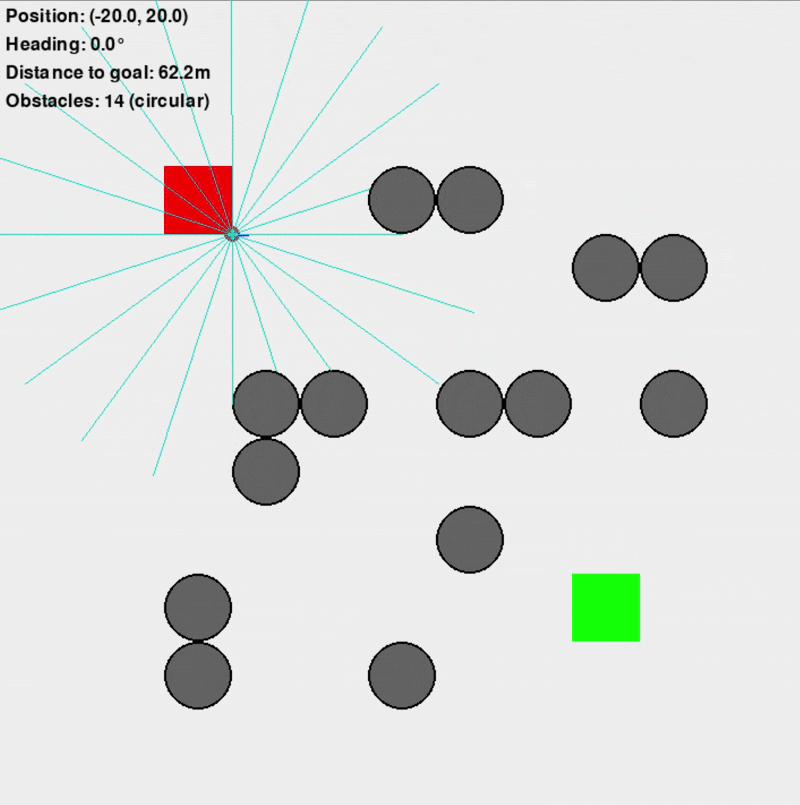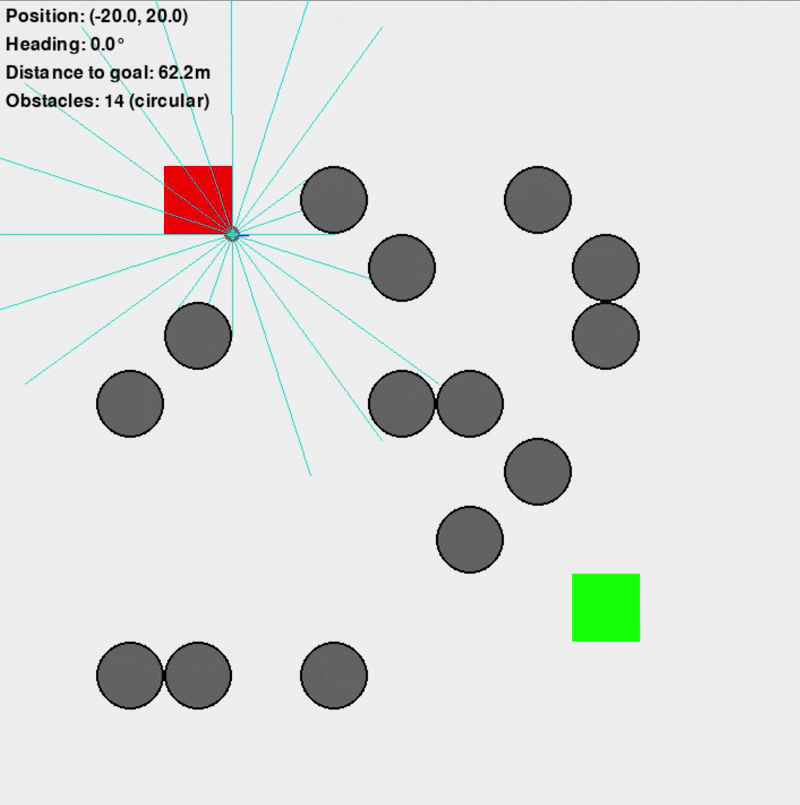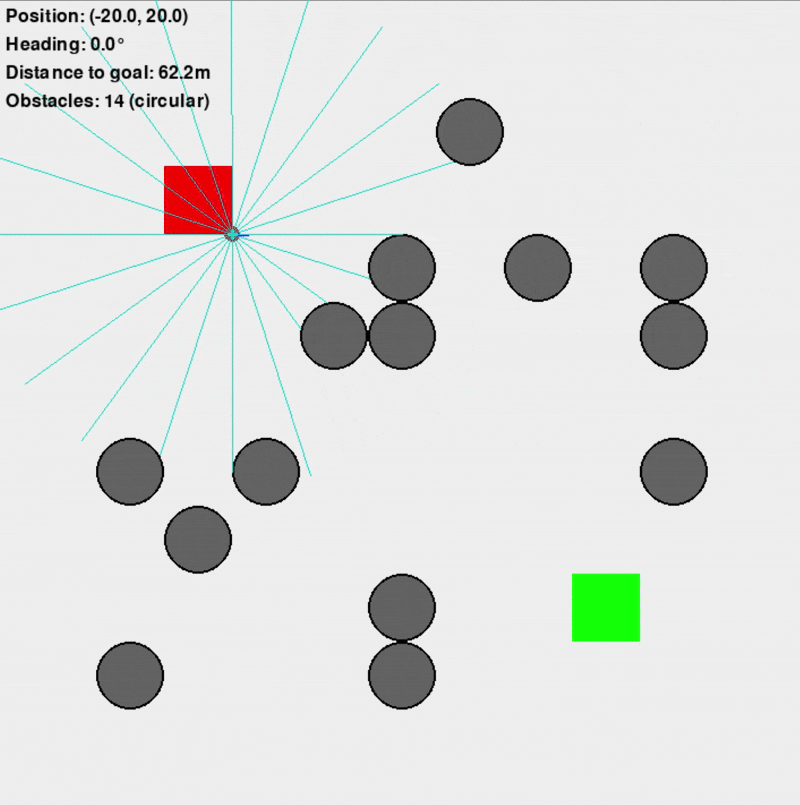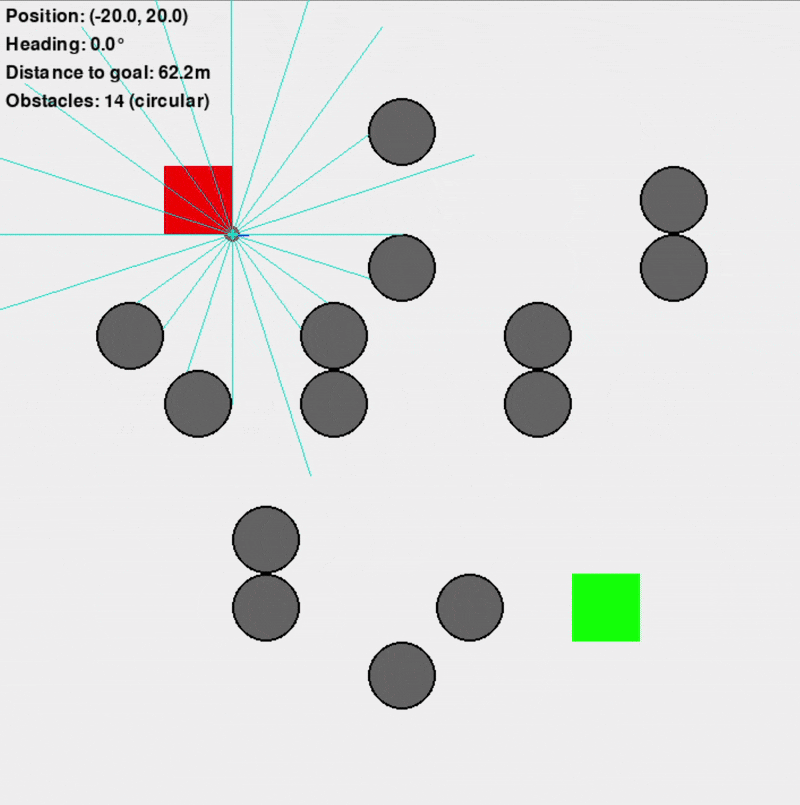
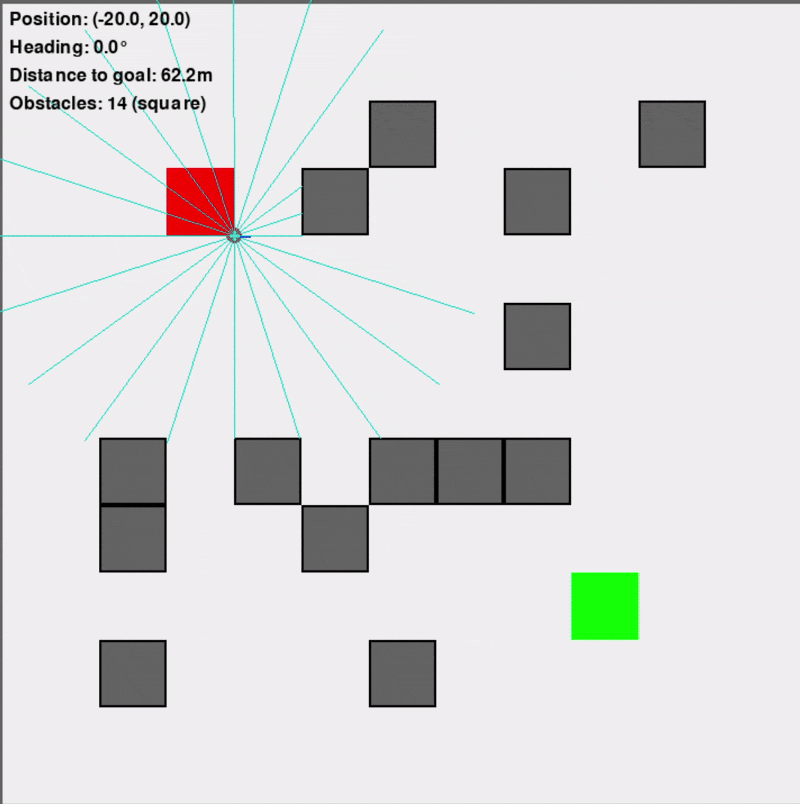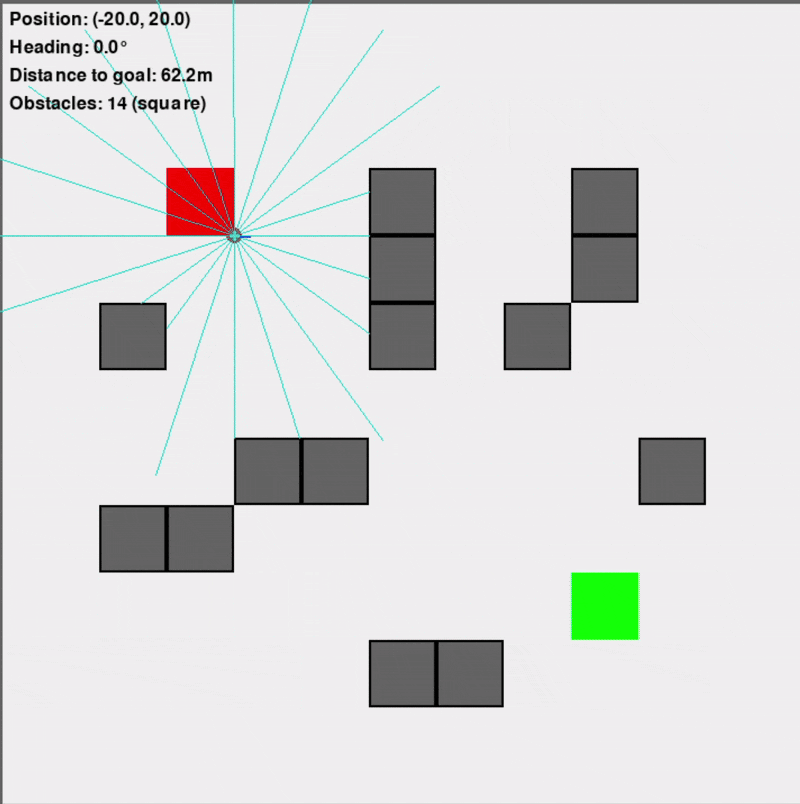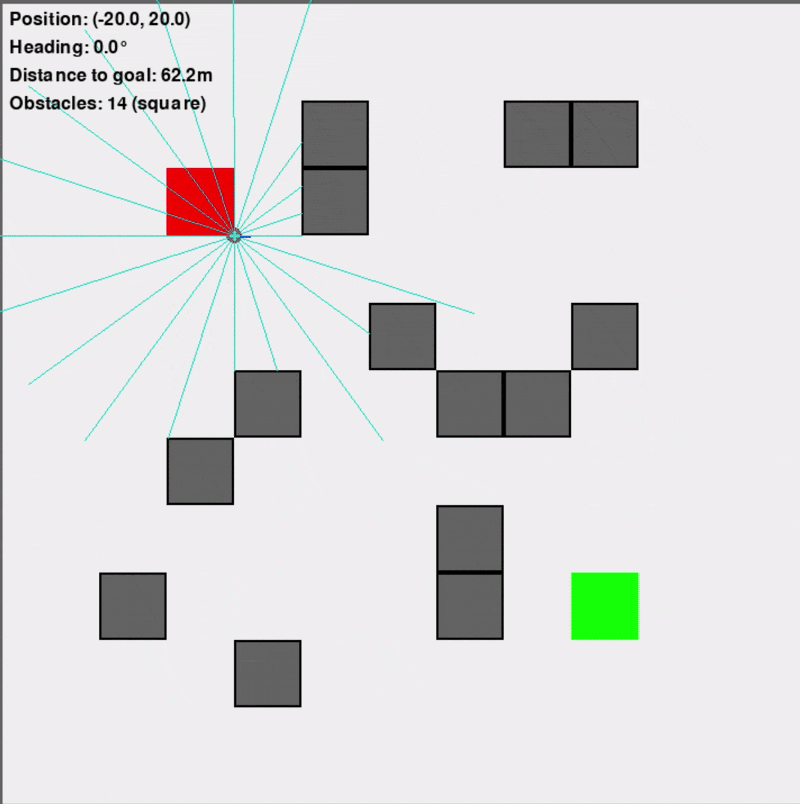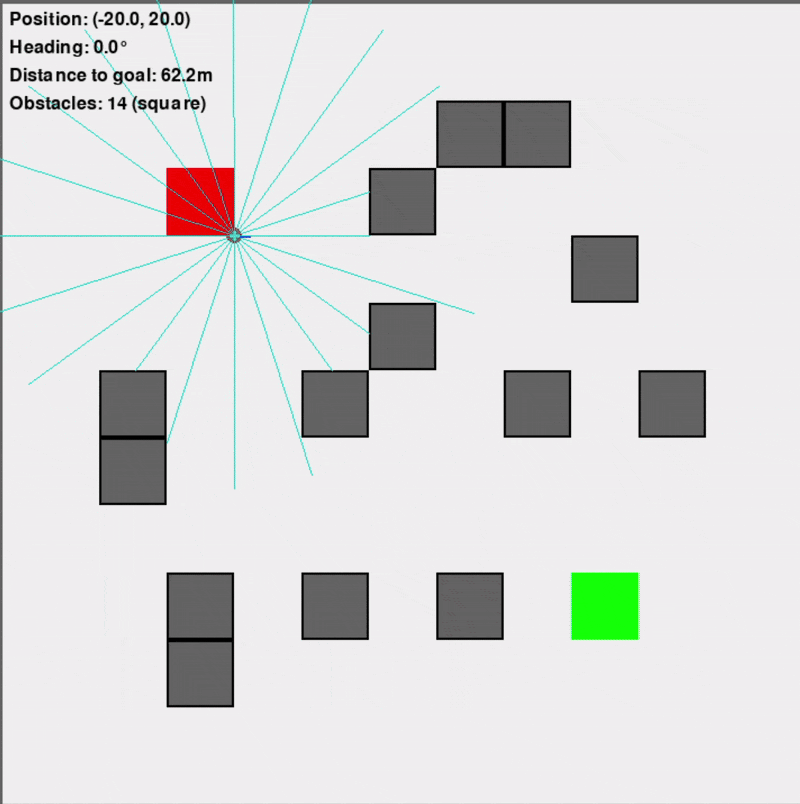
Custom Gymnasium Environment ("VectorizedDD")
This primary training environment was designed to replicate the navigation scenario efficiently, supporting vectorized (parallel) simulations for significantly faster training (10-100x faster than an equivalent Isaac Sim setup). It featured a square arena, randomly placed obstacles (configurable as square or circular to introduce uncertainty), and simulated Lidar sensors for the differential-drive robot.
NVIDIA Isaac Sim Environment
For higher-fidelity validation and to explore sim-to-sim transfer, the same navigation scenario was implemented in Isaac Sim. This platform offers physically accurate simulation with PhysX, realistic sensor models, and ROS integration capabilities. The goal was to transfer policies learned in the custom environment to Isaac Sim for more realistic testing.


We also experimented with Nick Germanis' gym-navigation environment to test our algorithms with discrete action spaces.
Algorithms Explored: PPO vs. SAC
The project focused on a comparative study of two state-of-the-art deep RL algorithms:
- Proximal Policy Optimization (PPO): An on-policy algorithm known for its stability. We implemented variants including PPO-CLIP (using a clipped surrogate objective) and PPO-KL (using KL-divergence as a constraint).
- Soft Actor-Critic (SAC): An off-policy algorithm incorporating entropy maximization for improved exploration and sample efficiency. Variants explored included Twin Critic vs. Single Critic architectures and different entropy management strategies (Adaptive, Fixed, None).
Both algorithms utilized similar 2-layer MLP neural network architectures for their policy and value/Q-networks.
Key Findings & Results
The comparative analysis yielded several significant insights into the performance of PPO and SAC for this navigation task:
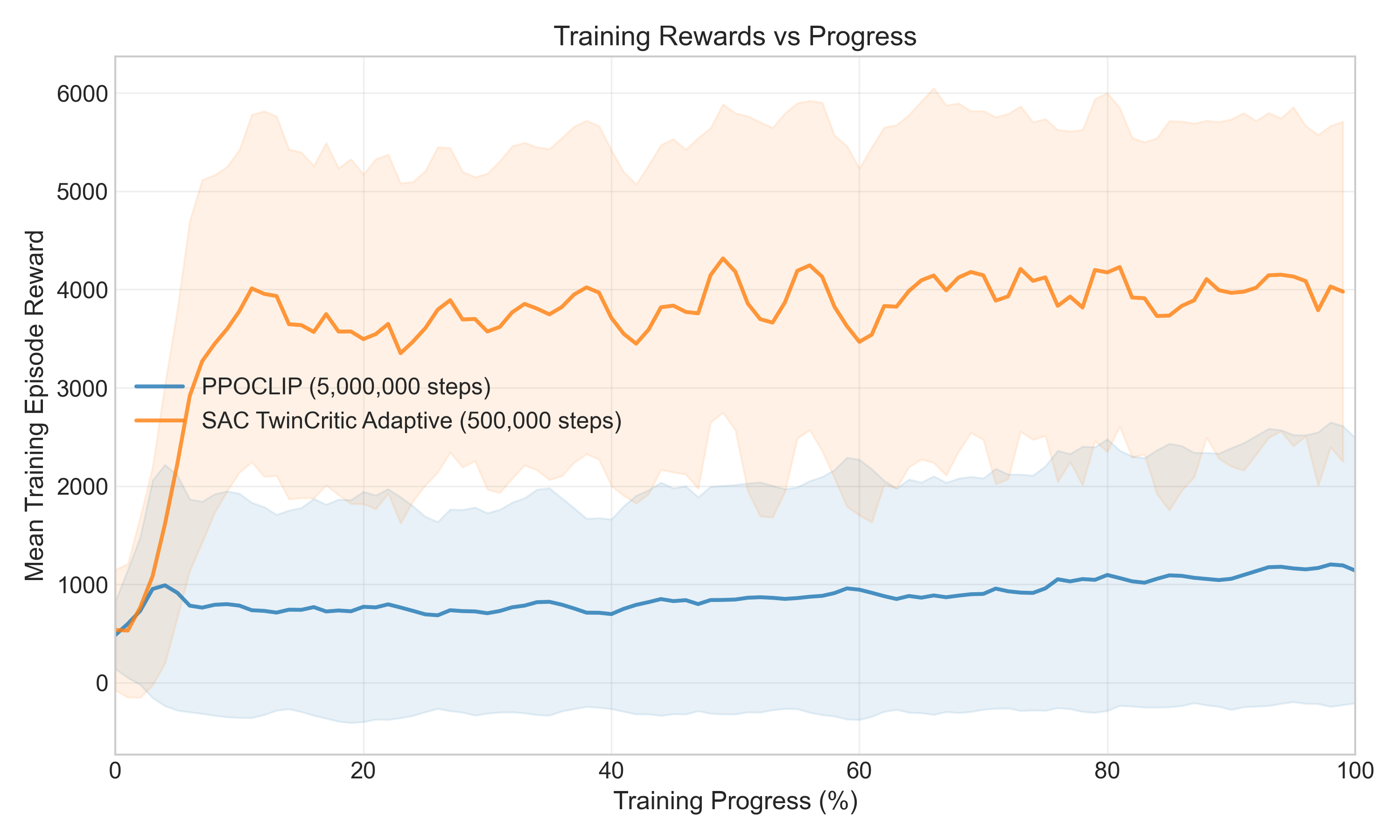
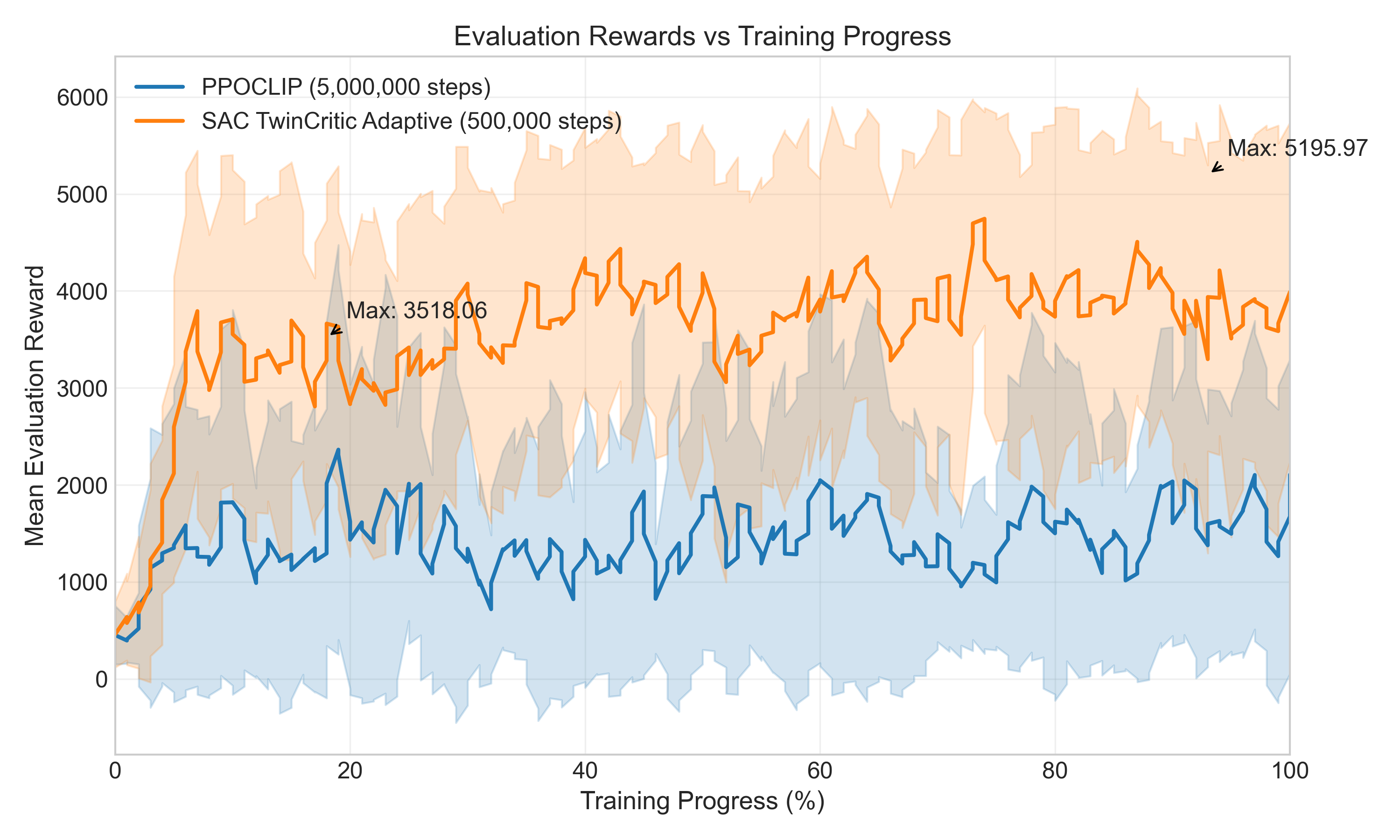
- Overall Performance: SAC dramatically outperformed PPO, achieving a 69.9% higher final reward and demonstrating approximately 36 times better sample efficiency. SAC policies also exhibited smoother trajectories and better goal-oriented behavior.
- PPO Variants: PPO-CLIP significantly outperformed PPO-KL in both training and evaluation, which was contrary to initial expectations about the stability benefits of KL-divergence constraints. This suggests that the simpler clipping mechanism in PPO-CLIP allowed for more effective policy updates in our variable environment.
- SAC Variants: The Twin Critic architecture was found to be a crucial component for SAC, offering an 8.5% performance improvement and better stability. Surprisingly, SAC variants with no explicit entropy bonus performed best in our navigation setup, potentially because the environment's inherent randomization provided sufficient exploration.
- Sim-to-Sim Transfer: Policies trained in the custom Gymnasium environment were successfully transferred to Isaac Sim. While requiring some fine-tuning, these policies demonstrated promising adaptation to the higher-fidelity simulation.
Challenges & Learnings
This project involved tackling several technical and conceptual challenges, including the complexity of implementing RL algorithm variants, designing realistic and efficient simulation environments, optimizing training performance, and managing the sim-to-sim transfer process. Limited computational resources also constrained the number of experimental trials. Despite these hurdles, the project provided valuable insights into the practical application of RL for robotic navigation.
Conclusion & Future Directions
This research successfully compared PPO and SAC for robot navigation under uncertainty, highlighting SAC's superior sample efficiency and final performance for this task. The viability of a sim-to-sim transfer approach was also demonstrated, offering a practical pathway for developing RL policies.
Future work could involve refining sim-to-real transfer, exploring hybrid PPO-SAC approaches, incorporating uncertainty-aware models, implementing curriculum learning, and extending the system to handle dynamic obstacles and multi-modal sensor fusion.
For more details, please visit the project repository: https://github.com/adnanamir010/IsaacRL_Maze